我們將抓取Yahoo奇摩網站中的「本周新片」的電影片名、電影英文片名、上映時間和網友期待度。
Yahoo 電影本週新片網址:https://movies.yahoo.com.tw/movie_thisweek.html
首先,我們需要先了解網頁的結構,以及要抓取的資料是在哪個HTML元素中(<div class="?")
可以直接在網頁上按F12或是滑鼠右鍵>檢查,就能看到HTML原始碼。
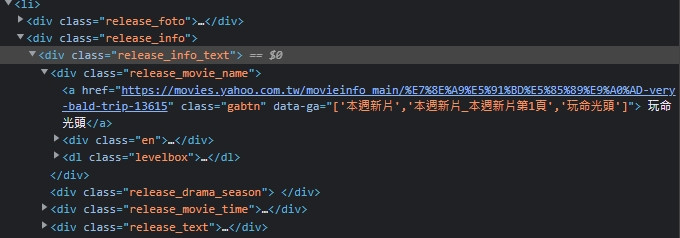
可以看到 release_info的class,代表一步電影資訊,開發人員程式碼中也會顯示區域,很人性化。
首先,先匯入相關套件。
import requests
from bs4 import BeautifulSoup
url= 'https://movies.yahoo.com.tw/movie_thisweek.html?guccounter=1'
response = requests.get(url=url)
soup = BeautifulSoup(response.text, 'lxml')
透過soup.find_all找出在網頁中所有的class為release_info的div標籤,取得每一部電影資料,他會回傳一個list,再透過for迴圈並使用find方法取出每一部電影的
最後再print出來。
for item in info_items:
name = item.find('div', 'release_movie_name').a.text.strip()
english_name = item.find('div', 'en').a.text.strip()
release_time = item.find('div', 'release_movie_time').text.split(':')[-1].strip()
level = item.find('div', 'leveltext').span.text.strip()
print('{}({}) 上映日:{} 期待度:{}'.format(name, english_name, release_time, level))
就可以看到以下資訊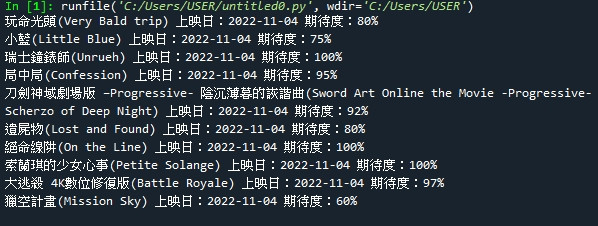
參考文章:
https://www.webscrapingpro.tw/yahoo-movie-web-scraping-using-python/


 iThome鐵人賽
iThome鐵人賽